背景
相信很多公司发展到一定规模,数据量达到千万级甚至亿级别的时候,开始考虑分库分表,最近我们团队一个同事接到别的团队交接过来的一个应用服务,每天的数据增量在1千万,由于时间紧迫,存储数据在Mysql中,经过短暂调研我们采用了分库分表的中间件Apache ShardingSphere的分库分表组件ShardingSphere-JDBC,这不是本文的重点,重点是我们做分库分表时,需要一次性创建几十甚至上百张分表,如果Ctrl+C和Ctrl+V也是极其累的,同事问我有木有简单的方法,减少重复劳动,我第一个想法就是用Mysql的存储过程或者函数批量创建表,解放生产力。
Mysql批量创建分表的过程
下面我以简化版的order表来举例说明操作过程
准备一个基本表order
CREATE TABLE `order` (
`order_id` bigint(20) NOT NULL COMMENT '住建ID',
`order_no` varchar(20) NOT NULL DEFAULT '' COMMENT '订单号',
`is_deleted` tinyint(2) NOT NULL DEFAULT '0' COMMENT '是否逻辑删除(0-否,1-是)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`remarks` varchar(255) NOT NULL DEFAULT '' COMMENT '备注',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单表';
创建一个批量创建order分表的存储过程
CREATE DEFINER=`root`@`%` PROCEDURE `batch_create_table_order`()
begin
declare i int default 0;
declare tab_name varchar(200) default '';
while i < 20 do
set tab_name = concat('create table order_',i, ' as select * from
`order` where 1=2;');
SET @SQL = CONCAT(tab_name);
PREPARE stmt FROM @SQL ;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
set i = i + 1;
end while;
end
执行存储过程
- 执行SQL命令
call batch_create_table_order();
- 执行结果和耗时:
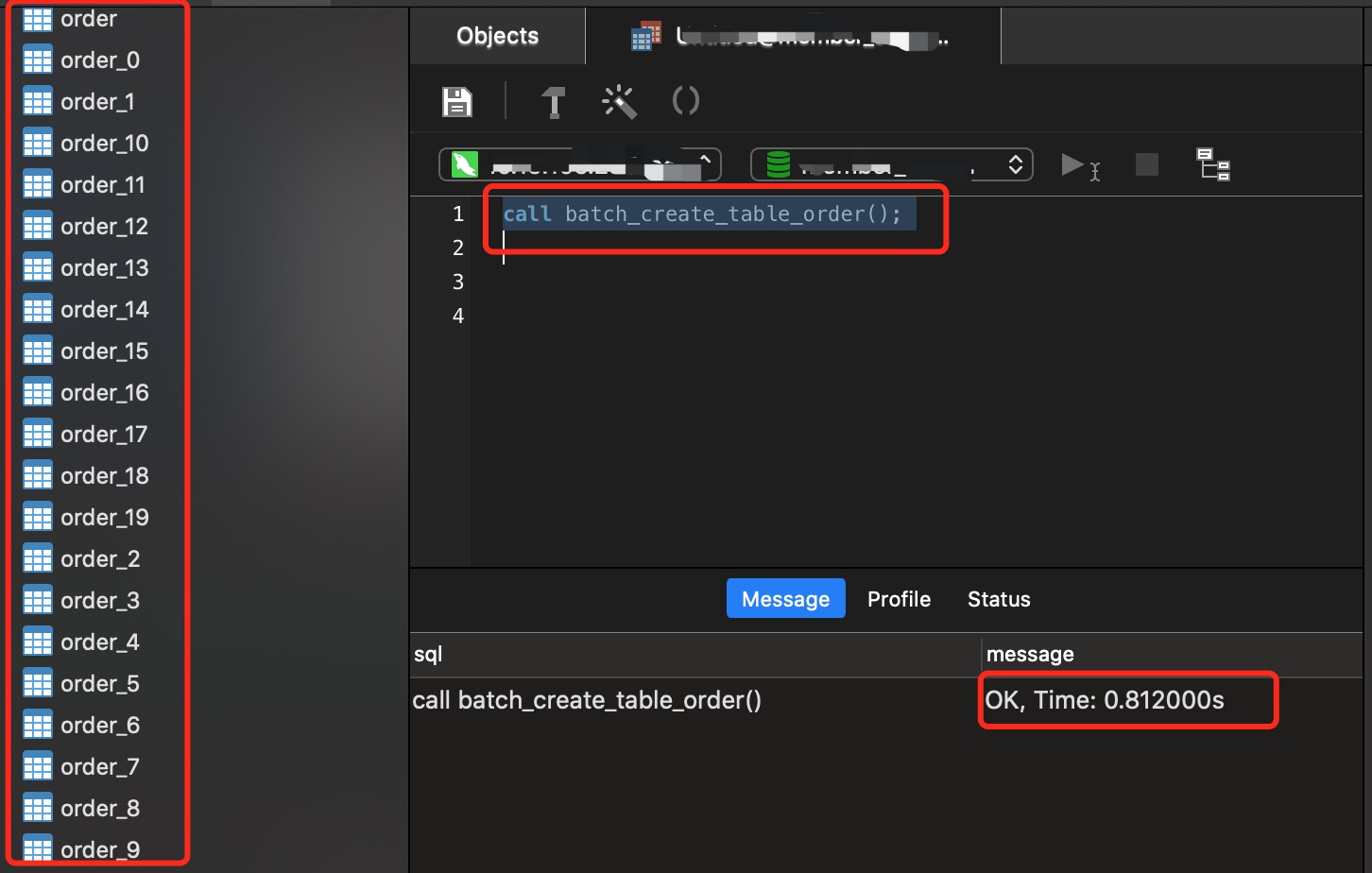
从执行的结果和耗时来看,不到1s就创建出了20张分表,如果是100张分表执行也只有1到2s,比起传统的Ctrl+C,Ctrl+V效率提升真是开心到飞起,多余的时间去刷刷虎扑,看看球,真香。